Automatic speech acknowledgment (ASR) is a reputable innovation that is extensively embraced for numerous applications such as teleconference, streamed video transcription and voice commands. While the difficulties for this innovation are focused around loud audio inputs, the visual stream in multimodal videos (e.g., TELEVISION, online modified videos) can offer strong hints for enhancing the toughness of ASR systems– this is called audiovisual ASR (AV-ASR).
Although lip movement can offer strong signals for speech acknowledgment and is the most typical location of focus for AV-ASR, the mouth is frequently not straight noticeable in videos in the wild (e.g., due to egocentric perspectives, face coverings, and low resolution) and for that reason, a brand-new emerging location of research study is unconstrained AV-ASR (e.g., AVATAR), which examines the contribution of whole visual frames, and not simply the mouth area.
Structure audiovisual datasets for training AV-ASR designs, nevertheless, is challenging. Datasets such as How2 and VisSpeech have actually been developed from educational videos online, however they are little in size. On the other hand, the designs themselves are generally big and include both visual and audio encoders, therefore they tend to overfit on these little datasets. However, there have actually been a variety of just recently launched massive audio-only designs that are greatly enhanced by means of massive training on enormous audio-only information acquired from audio books, such as LibriLight and LibriSpeech These designs include billions of criteria, are easily offered, and reveal strong generalization throughout domains.
With the above difficulties in mind, in “ AVFormer: Injecting Vision into Frozen Speech Designs for Zero-Shot AV-ASR“, we provide an easy technique for enhancing existing massive audio-only designs with visual info, at the very same time carrying out light-weight domain adjustment. AVFormer injects visual embeddings into a frozen ASR design (comparable to how Flamingo injects visual info into big language designs for vision-text jobs) utilizing light-weight trainable adaptors that can be trained on a percentage of weakly identified video information with minimum extra training time and criteria. We likewise present an easy curriculum plan throughout training, which we reveal is important to make it possible for the design to collectively process audio and visual info successfully. The resulting AVFormer design attains advanced zero-shot efficiency on 3 various AV-ASR standards (How2, VisSpeech and Ego4D), while likewise most importantly maintaining good efficiency on conventional audio-only speech acknowledgment standards (i.e., LibriSpeech).
 |
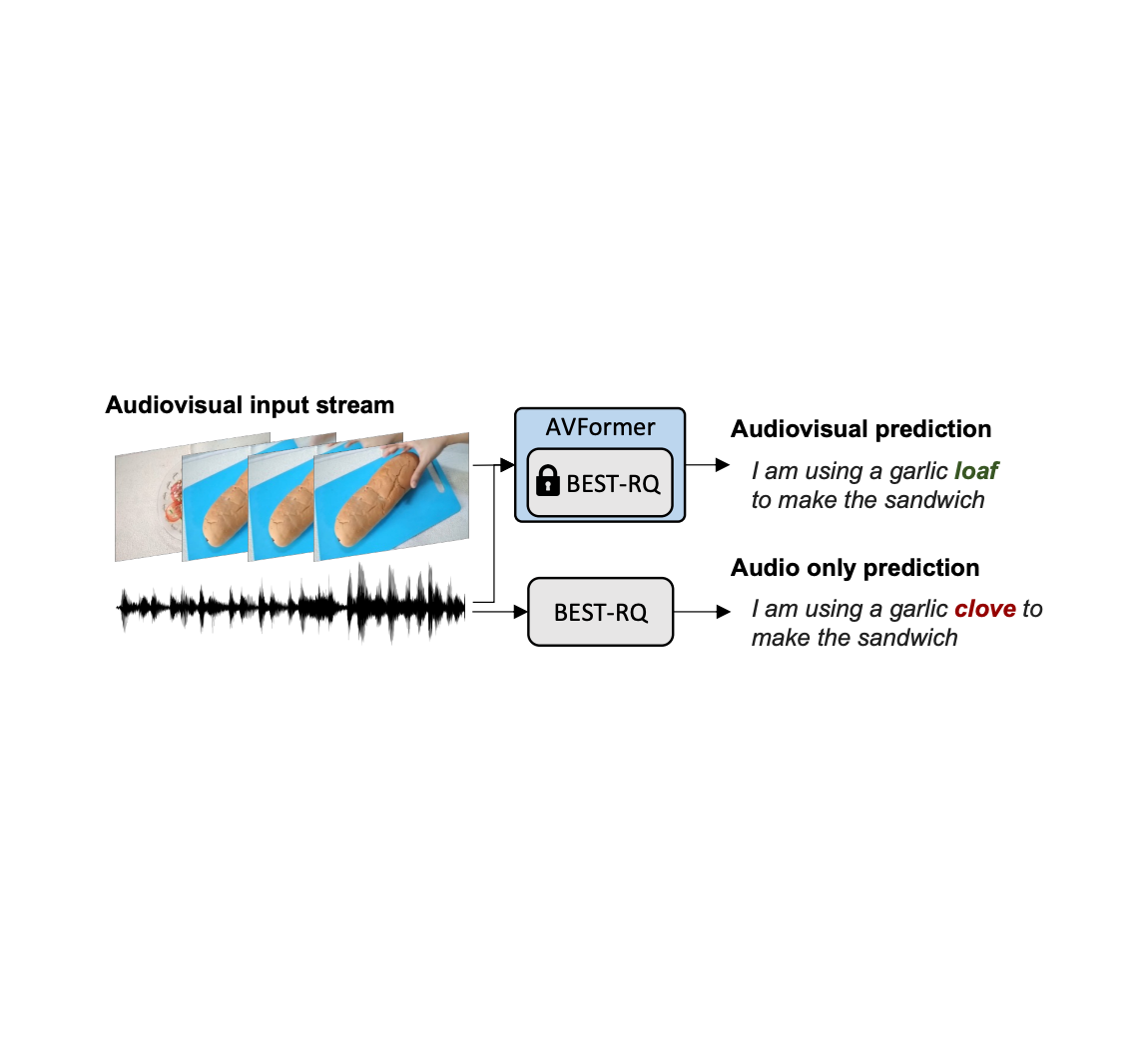
| Unconstrained audiovisual speech acknowledgment. We inject vision into a frozen speech design ( BEST-RQ, in grey) for zero-shot audiovisual ASR by means of light-weight modules to develop a criterion- and data-efficient design called AVFormer (blue). The visual context can offer practical hints for robust speech acknowledgment specifically when the audio signal is loud (the visual loaf of bread assists fix the audio-only error “clove” to “loaf” in the created records). |
Injecting vision utilizing light-weight modules
Our objective is to include visual understanding abilities to an existing audio-only ASR design while preserving its generalization efficiency to numerous domains (both AV and audio-only domains).
To attain this, we enhance an existing advanced ASR design ( Best-RQ) with the following 2 elements: (i) direct visual projector and (ii) light-weight adapters. The previous tasks visual functions in the audio token embedding area. This procedure enables the design to correctly link independently pre-trained visual function and audio input token representations. The latter then minimally customizes the design to include understanding of multimodal inputs from videos. We then train these extra modules on unlabeled web videos from the HowTo100M dataset, together with the outputs of an ASR design as pseudo ground reality, while keeping the remainder of the Best-RQ design frozen. Such light-weight modules make it possible for data-efficiency and strong generalization of efficiency.
We assessed our extended design on AV-ASR standards in a zero-shot setting, where the design is never ever trained on a by hand annotated AV-ASR dataset.
Curriculum knowing for vision injection
After the preliminary examination, we found empirically that with a naïve single round of joint training, the design has a hard time to discover both the adapters and the visual projectors in one go. To reduce this concern, we presented a two-phase curriculum knowing technique that decouples these 2 elements– domain adjustment and visual function combination– and trains the network in a consecutive way. In the very first stage, the adapter criteria are enhanced without feeding visual tokens at all. As soon as the adapters are trained, we include the visual tokens and train the visual forecast layers alone in the 2nd stage while the experienced adapters are kept frozen.
The very first phase concentrates on audio domain adjustment. By the 2nd stage, the adapters are entirely frozen and the visual projector should merely discover to produce visual triggers that task the visual tokens into the audio area. In this method, our curriculum discovering technique enables the design to integrate visual inputs in addition to adjust to brand-new audio domains in AV-ASR standards. We use each stage simply when, as an iterative application of rotating stages causes efficiency destruction.
 |
| General architecture and training treatment for AVFormer. The architecture includes a frozen Conformer encoder-decoder design, and a frozen CLIP encoder (frozen layers displayed in gray with a lock sign), in combination with 2 light-weight trainable modules – (i) visual forecast layer (orange) and traffic jam adapters (blue) to make it possible for multimodal domain adjustment. We propose a two-phase curriculum knowing technique: the adapters (blue) are very first trained with no visual tokens, after which the visual forecast layer (orange) is tuned while all the other parts are kept frozen. |
The plots listed below program that without curriculum knowing, our AV-ASR design is even worse than the audio-only standard throughout all datasets, with the space increasing as more visual tokens are included. On the other hand, when the proposed two-phase curriculum is used, our AV-ASR design carries out substantially much better than the standard audio-only design.
 |
| Impacts of curriculum knowing. Red and blue lines are for audiovisual designs and are revealed on 3 datasets in the zero-shot setting (lower WER % is much better). Utilizing the curriculum assists on all 3 datasets (for How2 (a) and Ego4D (c) it is important for outshining audio-only efficiency). Efficiency enhances up till 4 visual tokens, at which point it fills. |
Lead to zero-shot AV-ASR
We compare AVFormer to BEST-RQ, the audio variation of our design, and AVATAR, the cutting-edge in AV-ASR, for zero-shot efficiency on the 3 AV-ASR standards: How2, VisSpeech and Ego4D. AVFormer exceeds AVATAR and BEST-RQ on all, even outshining both AVATAR and BEST-RQ when they are trained on LibriSpeech and the complete set of HowTo100M. This is noteworthy due to the fact that for BEST-RQ, this includes training 600M criteria, while AVFormer just trains 4M criteria and for that reason needs just a little portion of the training dataset (5% of HowTo100M). Furthermore, we likewise assess efficiency on LibriSpeech, which is audio-only, and AVFormer exceeds both baselines.
.png) |
| Contrast to advanced approaches for zero-shot efficiency throughout various AV-ASR datasets. We likewise reveal efficiencies on LibriSpeech which is audio-only. Outcomes are reported as WER % (lower is much better). AVATAR and BEST-RQ are finetuned end-to-end (all criteria) on HowTo100M whereas AVFormer works successfully even with 5% of the dataset thanks to the little set of finetuned criteria. |
Conclusion
We present AVFormer, a light-weight technique for adjusting existing, frozen advanced ASR designs for AV-ASR. Our technique is useful and effective, and attains excellent zero-shot efficiency. As ASR designs get bigger and bigger, tuning the whole specification set of pre-trained designs ends up being unwise (a lot more so for various domains). Our technique perfectly enables both domain transfer and visual input blending in the very same, specification effective design.
Recognitions
This research study was performed by Paul Hongsuck Seo, Arsha Nagrani and Cordelia Schmid.