In today’s digital age, logging is an important element of application advancement and management, however effectively handling logs while adhering to information security guidelines can be a substantial obstacle. Zoom, in partnership with the AWS Data Laboratory group, established an ingenious architecture to conquer these obstacles and improve their logging and record removal procedures. In this post, we check out the architecture and the advantages it attends to Zoom and its users.
Application log obstacles: Information management and compliance
Application logs are a vital part of any application; they offer important info about the use and efficiency of the system. These logs are utilized for a range of functions, such as debugging, auditing, efficiency tracking, service intelligence, system upkeep, and security. Nevertheless, although these application logs are required for keeping and enhancing the application, they likewise present a fascinating obstacle. These application logs might include personally recognizable information, such as user names, e-mail addresses, IP addresses, and searching history, which produces an information personal privacy issue.
Laws such as the General Data Defense Policy (GDPR) and the California Customer Personal Privacy Act (CCPA) need companies to maintain application logs for a particular time period. The specific length of time needed for information storage differs depending upon the particular policy and the kind of information being kept. The factor for these information retention durations is to guarantee that business aren’t keeping individual information longer than required, which might increase the threat of information breaches and other security occurrences. This likewise assists guarantee that business aren’t utilizing individual information for functions besides those for which it was gathered, which might be an offense of personal privacy laws. These laws likewise offer people the right to ask for the removal of their individual information, likewise called the “best to be forgotten.” People deserve to have their individual information removed, without unnecessary hold-up.
So, on one hand, companies require to gather application log information to guarantee the correct performance of their services, and keep the information for a particular time period. However on the other hand, they might get demands from people to erase their individual information from the logs. This produces a balancing act for companies due to the fact that they should abide by both information retention and information removal requirements.
This concern ends up being significantly difficult for bigger companies that run in several nations and states, due to the fact that each nation and state might have their own guidelines and guidelines relating to information retention and removal. For instance, the Personal Info Defense and Electronic Files Act (PIPEDA) in Canada and the Australian Personal Privacy Act in Australia are comparable laws to GDPR, however they might have various retention durations or various exceptions. For that reason, companies huge or little should browse this complex landscape of information retention and removal requirements, while likewise guaranteeing that they remain in compliance with all suitable laws and guidelines.
Zoom’s preliminary architecture
Throughout the COVID-19 pandemic, using Zoom increased as a growing number of individuals were asked to work and participate in classes from house. The business needed to quickly scale its services to accommodate the rise and dealt with AWS to release capability throughout many Areas worldwide. With an unexpected boost in the a great deal of application endpoints, they needed to quickly develop their log analytics architecture and dealt with the AWS Data Laboratory group to rapidly model and release an architecture for their compliance usage case.
At Zoom, the information consumption throughput and efficiency requirements are extremely strict. Information needed to be consumed from a number of thousand application endpoints that produced over 30 million messages every minute, leading to over 100 TB of log information each day. The existing consumption pipeline included composing the information to Apache Hadoop HDFS storage through Apache Kafka initially and after that running daily tasks to move the information to consistent storage. This took a number of hours while likewise slowing the consumption and producing the capacity for information loss. Scaling the architecture was likewise a problem due to the fact that HDFS information would need to be walked around whenever nodes were included or eliminated. Moreover, transactional semantics on billions of records were required to assist satisfy compliance-related information erase demands, and the existing architecture of everyday batch tasks was operationally ineffective.
It was at this time, through discussions with the AWS account group, that the AWS Data Laboratory group got included to help in constructing an option for Zoom’s hyper-scale.
Option introduction
The AWS Data Laboratory uses sped up, joint engineering engagements in between clients and AWS technical resources to develop concrete deliverables that speed up information, analytics, expert system (AI), artificial intelligence (ML), serverless, and container modernization efforts. The Data Laboratory has 3 offerings: the Build Laboratory, the Style Laboratory, and Citizen Designer. Throughout the Build and Style Labs, AWS Data Laboratory Solutions Architects and AWS professionals supported Zoom particularly by supplying authoritative architectural assistance, sharing finest practices, constructing a working model, and eliminating technical obstructions to assist satisfy their production requirements.
Zoom and the AWS group (jointly described as “the group” moving forward) determined 2 significant workflows for information consumption and removal.
Information consumption workflow
The following diagram shows the information consumption workflow.

The group required to rapidly occupy countless Kafka messages in the dev/test environment to attain this. To speed up the procedure, we (the group) chose to utilize Amazon Managed Streaming for Apache Kafka (Amazon MSK), that makes it easy to consume and process streaming information in genuine time, and we were up and running in under a day.
To produce test information that looked like production information, the AWS Data Laboratory group developed a custom-made Python script that equally occupied over 1.2 billion messages throughout a number of Kafka partitions. To match the production setup in the advancement account, we needed to increase the cloud quota limitation through an assistance ticket.
We utilized Amazon MSK and the Glow Structured Streaming ability in Amazon EMR to consume and process the inbound Kafka messages with high throughput and low latency. Particularly, we placed the information from the source into EMR clusters at an optimum inbound rate of 150 million Kafka messages every 5 minutes, with each Kafka message holding 7– 25 log information records.
To save the information, we picked to utilize Apache Hudi as the table format. We went with Hudi due to the fact that it’s an open-source information management structure that supplies record-level insert, upgrade, and erase abilities on top of an immutable storage layer like Amazon Simple Storage Service (Amazon S3). In addition, Hudi is enhanced for dealing with big datasets and works well with Glow Structured Streaming, which was currently being utilized at Zoom.
After 150 million messages were buffered, we processed the messages utilizing Glow Structured Streaming on Amazon EMR and composed the information into Amazon S3 in Apache Hudi-compatible format every 5 minutes. We initially flattened the message range, producing a single record from the embedded range of messages. Then we included a special secret, called the Hudi record secret, to each message. This crucial permits Hudi to carry out record-level insert, upgrade, and erase operations on the information. We likewise drew out the field worths, consisting of the Hudi partition secrets, from inbound messages.
This architecture enabled end-users to query the information kept in Amazon S3 utilizing Amazon Athena with the AWS Glue Information Brochure or utilizing Apache Hive and Presto
Information removal workflow
The following diagram shows the information removal workflow.
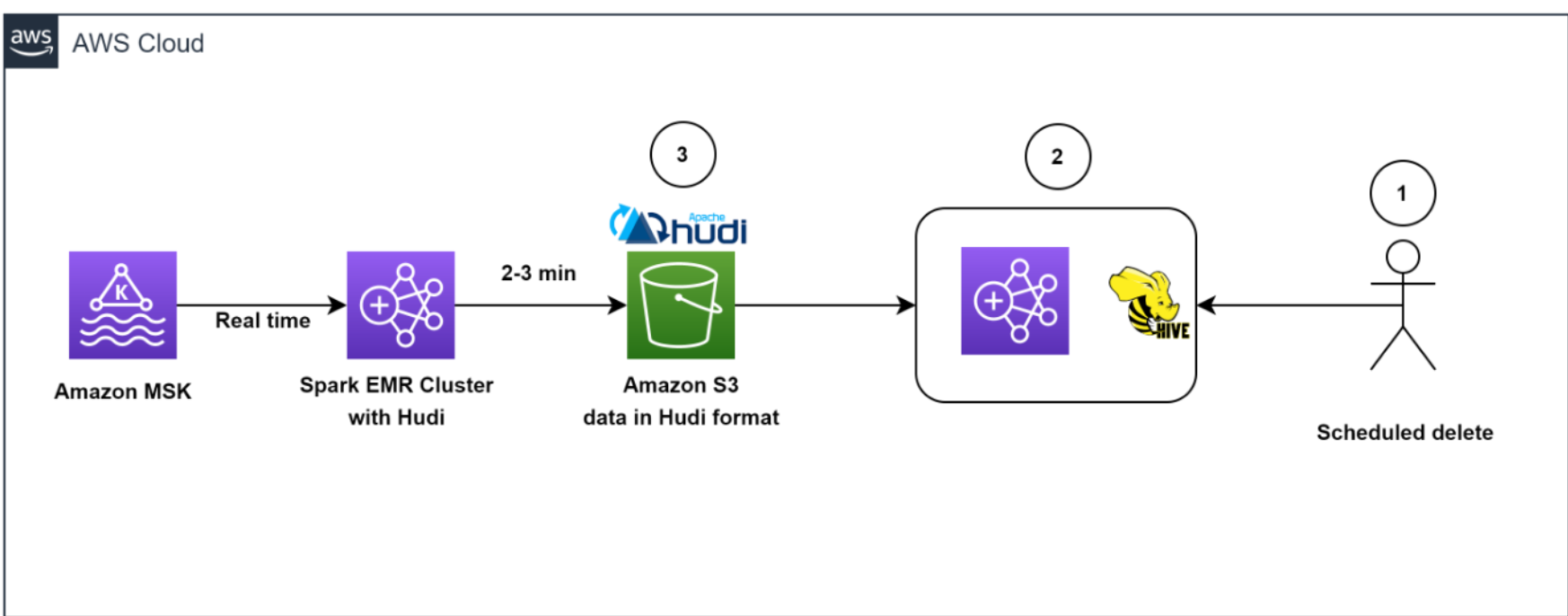
Our architecture permitted effective information removals. To assist abide by the customer-initiated information retention policy for GDPR deletes, set up tasks ran daily to recognize the information to be erased in batch mode.
We then spun up a short-term EMR cluster to run the GDPR upsert task to erase the records. The information was kept in Amazon S3 in Hudi format, and Hudi’s integrated index enabled us to effectively erase records utilizing blossom filters and file varieties. Due to the fact that just those files which contained the record secrets required to be checked out and reworded, it just took about 1– 2 minutes to erase 1,000 records out of the 1 billion records, which had actually formerly taken hours to finish as whole partitions read.
In general, our service made it possible for effective removal of information, which offered an extra layer of information security that was crucial for Zoom, because of its GDPR requirements.
Architecting to enhance scale, efficiency, and expense
In this area, we share the list below methods Zoom required to enhance scale, efficiency, and expense:
- Enhancing consumption
- Enhancing throughput and Amazon EMR usage
- Decoupling consumption and GDPR removal utilizing EMRFS
- Effective deletes with Apache Hudi
- Enhancing for low-latency checks out with Apache Hudi
- Tracking
Enhancing consumption
To keep the storage in Kafka lean and optimum, along with to get a real-time view of information, we developed a Glow task to check out inbound Kafka messages in batches of 150 million messages and composed to Amazon S3 in Hudi-compatible format every 5 minutes. Even throughout the preliminary phases of the model, when we had not begun scaling and tuning yet, we had the ability to effectively pack all Kafka messages regularly under 2.5 minutes utilizing the Amazon EMR runtime for Apache Glow
Enhancing throughput and Amazon EMR usage
We introduced a cost-optimized EMR cluster and changed from consistent circumstances groups to utilizing EMR circumstances fleets. We picked circumstances fleets due to the fact that we required the versatility to utilize Area Instances for job nodes and wished to diversify the threat of lacking capability for a particular circumstances enter our Accessibility Zone.
We began try out trial run by very first altering the variety of Kafka partitions from 400 to 1,000, and after that altering the variety of job nodes and circumstances types. Based upon the outcomes of the run, the AWS group created the suggestion to utilize Amazon EMR with 3 core nodes (r5.16 xlarge (64 vCPUs each)) and 18 job nodes utilizing Area fleet circumstances (a mix of r5.16 xlarge (64 vCPUs), r5.12 xlarge (48 vCPUs), r5.8 xlarge (32 vCPUs)). These suggestions assisted Zoom to decrease their Amazon EMR expenses by more than 80% while fulfilling their wanted efficiency objectives of consuming 150 million Kafka messages under 5 minutes.
Decoupling consumption and GDPR removal utilizing EMRFS
A popular advantage of separation of storage and calculate is that you can scale the 2 individually. However a not-so-obvious benefit is that you can decouple constant work from erratic work. Formerly information was kept in HDFS. Resource-intensive GDPR erase tasks and information motion tasks would contend for resources with the stream consumption, triggering a stockpile of more than 5 hours in upstream Kafka clusters, which was close to filling the Kafka storage (which just had 6 hours of information retention) and possibly triggering information loss. Unloading information from HDFS to Amazon S3 enabled us the flexibility to release independent short-term EMR clusters as needed to carry out information removal, assisting to guarantee that the continuous information consumption from Kafka into Amazon EMR is not starved for resources. This made it possible for the system to consume information every 5 minutes and total each Glow Streaming check out in 2– 3 minutes. Another adverse effects of utilizing EMRFS is a cost-optimized cluster, due to the fact that we got rid of dependence on Amazon Elastic Block Shop (Amazon EBS) volumes for over 300 TB storage that was utilized for 3 copies (consisting of 2 reproductions) of HDFS information. We now spend for just one copy of the information in Amazon S3, which supplies 11 nines of sturdiness and is fairly low-cost storage.
Effective deletes with Apache Hudi
What about the dispute in between consume composes and GDPR deletes when running simultaneously? This is where the power of Apache Hudi sticks out.
Apache Hudi supplies a table format for information lakes with transactional semantics that allows the separation of consumption work and updates when run simultaneously. The system had the ability to regularly erase 1,000 records in less than a minute. There were some restrictions in concurrent composes in Apache Hudi 0.7.0, however the Amazon EMR group rapidly resolved this by back-porting Apache Hudi 0.8.0, which supports positive concurrency control, to the existing (at the time of the AWS Data Laboratory partnership) Amazon EMR 6.4 release. This conserved time in screening and permitted a fast shift to the brand-new variation with very little screening. This allowed us to query the information straight utilizing Athena rapidly without needing to spin up a cluster to run advertisement hoc questions, along with to query the information utilizing Presto, Trino, and Hive. The decoupling of the storage and calculate layers offered the versatility to not just query information throughout various EMR clusters, however likewise erase information utilizing a totally independent short-term cluster.
Enhancing for low-latency checks out with Apache Hudi
To enhance for low-latency checks out with Apache Hudi, we required to resolve the concern of a lot of little files being developed within Amazon S3 due to the constant streaming of information into the information lake.
We used Apache Hudi’s functions to tune file sizes for optimum querying. Particularly, we lowered the degree of parallelism in Hudi from the default worth of 1,500 to a lower number. Parallelism describes the variety of threads utilized to compose information to Hudi; by decreasing it, we had the ability to develop bigger files that were more optimum for querying.
Due to the fact that we required to enhance for high-volume streaming consumption, we picked to carry out the combine on read table type (rather of copy on compose) for our work. This table type enabled us to rapidly consume the inbound information into delta files in row format (Avro) and asynchronously compact the delta submits into columnar Parquet apply for quick checks out. To do this, we ran the Hudi compaction task in the background. Compaction is the procedure of combining row-based delta files to produce brand-new variations of columnar files. Due to the fact that the compaction task would utilize extra calculate resources, we changed the degree of parallelism for insertion to a lower worth of 1,000 to represent the extra resource use. This modification enabled us to develop bigger files without compromising efficiency throughput.
In general, our method to enhancing for low-latency checks out with Apache Hudi enabled us to much better handle file sizes and enhance the general efficiency of our information lake.
Tracking
The group kept an eye on MSK clusters with Prometheus (an open-source tracking tool). In addition, we showcased how to keep track of Glow streaming tasks utilizing Amazon CloudWatch metrics. To find out more, describe Screen Glow streaming applications on Amazon EMR
Results
The partnership in between Zoom and the AWS Data Laboratory showed considerable enhancements in information consumption, processing, storage, and removal utilizing an architecture with Amazon EMR and Apache Hudi. One crucial advantage of the architecture was a decrease in facilities expenses, which was attained through using cloud-native innovations and the effective management of information storage. Another advantage was an enhancement in information management abilities.
We revealed that the expenses of EMR clusters can be lowered by about 82% while bringing the storage costs down by about 90% compared to the previous HDFS-based architecture. All of this while making the information readily available in the information lake within 5 minutes of consumption from the source. We likewise showed that information removals from an information lake including several petabytes of information can be carried out a lot more effectively. With our enhanced method, we had the ability to erase roughly 1,000 records in simply 1– 2 minutes, as compared to the formerly needed 3 hours or more.
Conclusion
In conclusion, the log analytics procedure, which includes gathering, processing, keeping, evaluating, and erasing log information from different sources such as servers, applications, and gadgets, is crucial to assist companies in working to satisfy their service resiliency, security, efficiency tracking, troubleshooting, and compliance requirements, such as GDPR.
This post shared what Zoom and the AWS Data Laboratory group have actually achieved together to fix crucial information pipeline obstacles, and Zoom has actually extended the service even more to enhance extract, change, and load (ETL) tasks and resource effectiveness. Nevertheless, you can likewise utilize the architecture patterns provided here to rapidly develop affordable and scalable services for other usage cases. Please connect to your AWS group for more details or contact Sales
About the Authors
 Sekar Srinivasan is a Sr. Expert Solutions Designer at AWS concentrated on Big Data and Analytics. Sekar has more than twenty years of experience dealing with information. He is enthusiastic about assisting clients develop scalable services improving their architecture and producing insights from their information. In his extra time he likes to deal with non-profit tasks concentrated on impoverished Kid’s education.
Sekar Srinivasan is a Sr. Expert Solutions Designer at AWS concentrated on Big Data and Analytics. Sekar has more than twenty years of experience dealing with information. He is enthusiastic about assisting clients develop scalable services improving their architecture and producing insights from their information. In his extra time he likes to deal with non-profit tasks concentrated on impoverished Kid’s education.
 Chandra Dhandapani is a Senior Solutions Designer at AWS, where he concentrates on producing services for clients in Analytics, AI/ML, and Databases. He has a great deal of experience in structure and scaling applications throughout various markets consisting of Health care and Fintech. Beyond work, he is a devoted tourist and delights in sports, reading, and home entertainment.
Chandra Dhandapani is a Senior Solutions Designer at AWS, where he concentrates on producing services for clients in Analytics, AI/ML, and Databases. He has a great deal of experience in structure and scaling applications throughout various markets consisting of Health care and Fintech. Beyond work, he is a devoted tourist and delights in sports, reading, and home entertainment.
 Amit Kumar Agrawal is a Senior Solutions Designer at AWS, based out of San Francisco Bay Location. He deals with big tactical ISV clients to designer cloud services that resolve their service obstacles. Throughout his downtime he delights in checking out the outdoors with his household.
Amit Kumar Agrawal is a Senior Solutions Designer at AWS, based out of San Francisco Bay Location. He deals with big tactical ISV clients to designer cloud services that resolve their service obstacles. Throughout his downtime he delights in checking out the outdoors with his household.
 Viral Shah is a Analytics Sales Expert dealing with AWS for 5 years assisting clients to be effective in their information journey. He has more than 20+ years of experience dealing with business clients and start-ups, mainly in the information and database area. He enjoys to take a trip and invest quality time with his household.
Viral Shah is a Analytics Sales Expert dealing with AWS for 5 years assisting clients to be effective in their information journey. He has more than 20+ years of experience dealing with business clients and start-ups, mainly in the information and database area. He enjoys to take a trip and invest quality time with his household.