This post is a visitor post co-written with SeonJeong Lee, JaeRyun Yim, and HyeonSeok Yang from Encored Technologies.
Encored Technologies (Encored) is an energy IT business in Korea that assists their consumers produce greater earnings and lower functional expenses in renewable resource markets by offering numerous AI-based options. Encored establishes artificial intelligence (ML) applications forecasting and enhancing numerous energy-related procedures, and their crucial effort is to anticipate the quantity of power created at renewable resource power plants.
In this post, we share how Encored runs information engineering pipelines for containerized ML applications on AWS and how they utilize AWS Lambda to attain efficiency enhancement, expense decrease, and functional effectiveness. We likewise show how to utilize AWS services to consume and process GRIB (GRIdded Binary) format information, which is a file format frequently utilized in meteorology to shop and exchange weather condition and environment information in a compressed binary type. It enables effective information storage and transmission, in addition to simple adjustment of the information utilizing specialized software application.
Service and technical obstacle
Encored is broadening their service into several nations to offer power trading services for end consumers. The quantity of information and the variety of power plants they require to gather information are quickly increasing in time. For instance, the volume of information needed for training among the ML designs is more than 200 TB. To satisfy the growing requirements of business, the information science and platform group required to accelerate the procedure of providing design outputs. As an option, Encored intended to move existing information and run ML applications in the AWS Cloud environment to effectively process a scalable and robust end-to-end information and ML pipeline.
Option introduction
The main goal of the service is to establish an enhanced information consumption pipeline that attends to the scaling obstacles associated with information consumption. Throughout its previous release in an on-premises environment, the time required to process information from consumption to preparing the training dataset surpassed the necessary service level arrangement (RUN-DOWN NEIGHBORHOOD). Among the input datasets needed for ML designs is weather condition information provided by the Korea Meteorological Administration (KMA). In order to utilize the GRIB datasets for the ML designs, Encored required to prepare the raw information to make it appropriate for structure and training ML designs. The primary step was to transform GRIB to the Parquet file format.
Encored utilized Lambda to run an existing information consumption pipeline integrated in a Linux-based container image. Lambda is a calculate service that lets you run code without provisioning or handling servers. Lambda runs your code on a high-availability calculate facilities and carries out all of the administration of the calculate resources, consisting of server and os upkeep, capability provisioning and automated scaling, and logging. AWS Lambda is activated to consume and process GRIB information files when they are submitted to Amazon Simple Storage Service (Amazon S3). When the files are processed, they are kept in Parquet format in the other S3 container. Encored gets GRIB files throughout the day, and whenever brand-new files show up, an AWS Lambda function runs a container image signed up in Amazon Elastic Container Pc Registry (ECR). This event-based pipeline activates a tailored information pipeline that is packaged in a container-based service. Leveraging Amazon AWS Lambda, this service is cost-efficient, scalable, and high-performing. Encored usages Python as their favored language.
The following diagram shows the service architecture.
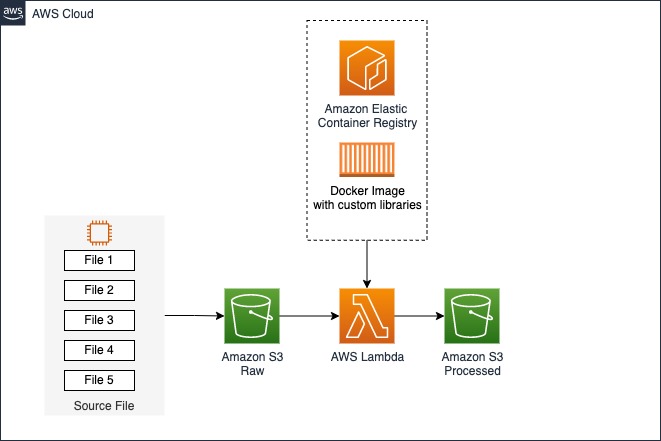
For data-intensive jobs such as extract, change, and load (ETL) tasks and ML reasoning, Lambda is a perfect service since it provides numerous crucial advantages, consisting of fast scaling to satisfy need, automated scaling to absolutely no when not in usage, and S3 occasion activates that can start actions in reaction to object-created occasions. All this adds to constructing a scalable and cost-efficient information event-driven pipeline. In addition to these advantages, Lambda enables you to set up ephemeral storage (/ tmp) in between 512– 10,240 MB. Encored utilized this storage for their information application when checking out or composing information, allowing them to enhance efficiency and cost-effectiveness. Moreover, Lambda’s pay-per-use rates design suggests that users just spend for the calculate time in usage, making it an economical service for a large range of usage cases.
Requirements
For this walkthrough, you must have the following:
Construct your application needed for your Docker image
The primary step is to establish an application that can consume and process files. This application checks out the container name and things crucial passed from a trigger contributed to Lambda function. The processing reasoning includes 3 parts: downloading the file from Amazon S3 into ephemeral storage (/ tmp), parsing the GRIB formatted information, and conserving the parsed information to Parquet format.
The client has a Python script (for instance, app.py) that carries out these jobs as follows:
Prepare a Docker file
The 2nd action is to produce a Docker image utilizing an AWS base image. To attain this, you can produce a brand-new Dockerfile utilizing a full-screen editor on your regional device. This Dockerfile ought to consist of 2 environment variables:
LAMBDA_TASK_ROOT=/ var/taskLAMBDA_RUNTIME_DIR=/ var/runtime
It is essential to set up any reliances under the $ {LAMBDA_TASK_ROOT} directory site together with the function handler to make sure that the Lambda runtime can find them when the function is conjured up. Describe the readily available Lambda base images for customized runtime for additional information.
Construct a Docker image
The 3rd action is to develop your Docker image utilizing the docker develop command. When running this command, make certain to go into a name for the image. For instance:
docker develop -t process-grib.
In this example, the name of the image is process-grib You can pick any name you like for your Docker image.
Upload the image to the Amazon ECR repository
Your container image requires to live in an Amazon Elastic Container Pc Registry (Amazon ECR) repository. Amazon ECR is a totally handled container computer system registry offering high-performance hosting, so you can dependably release application images and artifacts anywhere. For guidelines on producing an ECR repository, describe Developing a personal repository
The primary step is to verify the Docker CLI to your ECR computer system registry as follows:
The 2nd action is to tag your image to match your repository name, and release the image to Amazon ECR utilizing the docker push command:
Deploy Lambda operates as container images
To produce your Lambda function, finish the following actions:
- On the Lambda console, pick Functions in the navigation pane.
- Select Produce function
- Select the Container image alternative.
- For Function name, go into a name.
- For Container image URI, offer a container image. You can go into the ECR image URI or search for the ECR image.
- Under Container image bypasses, you can bypass setup settings such as the entry point or working directory site that are consisted of in the Dockerfile.
- Under Approvals, broaden Modification default execution function
- Select to produce a brand-new function or utilize an existing function.
- Select Produce function
Secret factors to consider
To manage a big quantity of information simultaneously and rapidly, Encored required to save GRIB formatted files in the ephemeral storage (/ tmp) that includes Lambda. To attain this requirement, Encored utilized tempfile.NamedTemporaryFile, which enables users to produce short-term files quickly that are erased when no longer required. With Lambda, you can set up ephemeral storage in between 512 MB– 10,240 MB for reading or composing information, permitting you to run ETL tasks, ML reasoning, or other data-intensive work.
Service result
Hyoseop Lee (CTO at Encored Technologies) stated, “Encored has actually experienced favorable results given that moving to AWS Cloud. At first, there was an understanding that running work on AWS would be more costly than utilizing an on-premises environment. Nevertheless, we found that this was not the case once we began running our applications on AWS. Among the most remarkable elements of AWS services is the versatile architecture alternatives it attends to processing, saving, and accessing big volumes of information that are just needed rarely.”
Conclusion
In this post, we covered how Encored developed serverless information pipelines with Lambda and Amazon ECR to attain efficiency enhancement, expense decrease, and functional effectiveness.
Encored effectively developed an architecture that will support their international growth and boost technical abilities through AWS services and the AWS Data Laboratory program. Based upon the architecture and numerous internal datasets Encored has actually combined and curated, Encored strategies to offer renewable resource forecasting and energy trading services.
Thanks for reading this post and ideally you discovered it beneficial. To accelerate your digital improvement with ML, AWS is readily available to support you by offering authoritative architectural assistance on a specific usage case, sharing finest practices, and eliminating technical obstructions. You’ll leave the engagement with an architecture or working model that is customized fit to your requirements, a course to production, and much deeper understanding of AWS services. Please call your AWS Account Supervisor or Solutions Designer to start. If you do not have an AWS Account Supervisor, please contact Sales
To get more information about ML reasoning usage cases with Lambda, take a look at the following post:
These resources will offer you with important insights and useful examples of how to utilize Lambda for ML reasoning.
About the Authors
 SeonJeong Lee is the Head of Algorithms at Encored. She is an information specialist who discovers comfort from stunning codes and solutions.
SeonJeong Lee is the Head of Algorithms at Encored. She is an information specialist who discovers comfort from stunning codes and solutions.
 JaeRyun Yim is a Senior Citizen Data Researcher at Encored. He is making every effort to enhance both work and life by concentrating on simpleness and essence in my work.
JaeRyun Yim is a Senior Citizen Data Researcher at Encored. He is making every effort to enhance both work and life by concentrating on simpleness and essence in my work.
 HyeonSeok Yang is the platform group lead at Encored. He constantly aims to deal with enthusiasm and spirit to keep challenging like a junior designer, and end up being a good example for others.
HyeonSeok Yang is the platform group lead at Encored. He constantly aims to deal with enthusiasm and spirit to keep challenging like a junior designer, and end up being a good example for others.
 Younggu Yun operates at AWS Data Laboratory in Korea. His function includes assisting consumers throughout the APAC area satisfy their service goals and get rid of technical obstacles by offering authoritative architectural assistance, sharing finest practices, and structure ingenious options together.
Younggu Yun operates at AWS Data Laboratory in Korea. His function includes assisting consumers throughout the APAC area satisfy their service goals and get rid of technical obstacles by offering authoritative architectural assistance, sharing finest practices, and structure ingenious options together.