Individuals have the amazing capability to take in a significant quantity of details (approximated to be ~ 10 10 bits/s getting in the retina) and selectively address a couple of task-relevant and intriguing areas for additional processing (e.g., memory, understanding, action). Designing human attention (the outcome of which is typically called a saliency design) has actually for that reason been of interest throughout the fields of neuroscience, psychology, human-computer interaction (HCI) and computer system vision The capability to forecast which areas are most likely to draw in attention has various essential applications in locations like graphics, photography, image compression and processing, and the measurement of visual quality.
We have actually formerly talked about the possibility of speeding up eye motion research study utilizing artificial intelligence and smartphone-based look evaluation, which earlier necessary specialized hardware costing as much as $30,000 per system. Associated research study consists of “ Want To Speak“, which assists users with ease of access requirements (e.g., individuals with ALS) to interact with their eyes, and the just recently released “ Differentially personal heatmaps” method to calculate heatmaps, like those for attention, while securing users’ personal privacy.
In this blog site, we provide 2 documents (one from CVPR 2022, and one simply accepted to CVPR 2023) that highlight our current research study in the location of human attention modeling: “ Deep Saliency Prior for Minimizing Visual Interruption” and “ Knowing from Special Viewpoints: User-aware Saliency Modeling“, together with current research study on saliency driven progressive filling for image compression ( 1, 2). We display how predictive designs of human attention can make it possible for wonderful user experiences such as image modifying to lessen visual mess, interruption or artifacts, image compression for faster loading of web pages or apps, and directing ML designs towards more instinctive human-like analysis and design efficiency. We concentrate on image modifying and image compression, and talk about current advances in modeling in the context of these applications.
Attention-guided image modifying
Human attention designs generally take an image as input (e.g., a natural image or a screenshot of a website), and forecast a heatmap as output The forecasted heatmap on the image is examined versus ground-truth attention information, which are usually gathered by an eye tracker or estimated by means of mouse hovering/clicking Previous designs leveraged handcrafted functions for visual ideas, like color/brightness contrast, edges, and shape, while more current methods immediately find out discriminative functions based upon deep neural networks, from convolutional and persistent neural networks to more current vision transformer networks
In “ Deep Saliency Prior for Minimizing Visual Interruption” (more details on this job website), we utilize deep saliency designs for significant yet aesthetically reasonable edits, which can considerably alter an observer’s attention to various image areas. For instance, getting rid of disruptive items in the background can lower mess in images, causing increased user fulfillment. Likewise, in video conferencing, decreasing mess in the background might increase concentrate on the primary speaker ( example demonstration here).
To explore what kinds of modifying results can be accomplished and how these impact audiences’ attention, we established an optimization structure for directing visual attention in images utilizing a differentiable, predictive saliency design. Our technique utilizes a cutting edge deep saliency design. Offered an input image and a binary mask representing the distractor areas, pixels within the mask will be modified under the assistance of the predictive saliency design such that the saliency within the masked area is lowered. To make certain the modified image is natural and reasonable, we thoroughly pick 4 image modifying operators: 2 basic image modifying operations, particularly recolorization and image warping (shift); and 2 found out operators (we do not specify the modifying operation clearly), particularly a multi-layer convolution filter, and a generative design ( GAN).
With those operators, our structure can produce a range of effective results, with examples in the figure listed below, consisting of recoloring, inpainting, camouflage, things modifying or insertion, and facial quality modifying. Notably, all these results are driven entirely by the single, pre-trained saliency design, with no extra guidance or training. Keep in mind that our objective is not to take on devoted approaches for producing each result, however rather to show how numerous modifying operations can be assisted by the understanding ingrained within deep saliency designs.
 |
| Examples of decreasing visual interruptions, assisted by the saliency design with a number of operators. The distractor area is marked on top of the saliency map (red border) in each example. |
Improving experiences with user-aware saliency modeling
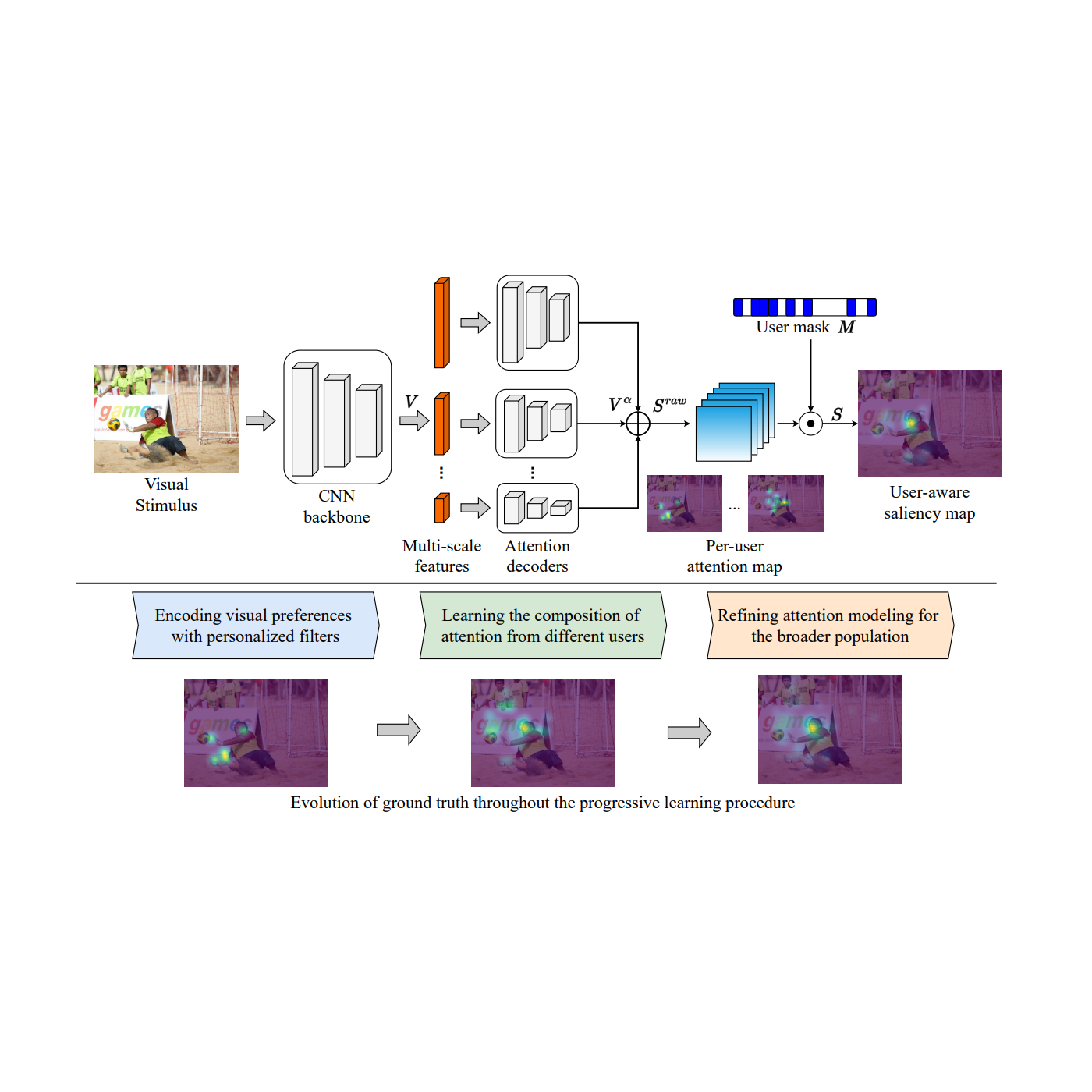
Prior research study presumes a single saliency design for the entire population. Nevertheless, human attention differs in between people– while the detection of prominent ideas is relatively constant, their order, analysis, and look circulations can vary considerably. This uses chances to develop customized user experiences for people or groups. In “ Knowing from Special Viewpoints: User-aware Saliency Modeling“, we present a user-aware saliency design, the very first that can forecast attention for one user, a group of users, and the basic population, with a single design.
As displayed in the figure listed below, core to the design is the mix of each individual’s visual choices with a per-user attention map and adaptive user masks. This needs per-user attention annotations to be offered in the training information, e.g., the OSIE mobile look dataset for natural images; FiWI and WebSaliency datasets for websites. Rather of anticipating a single saliency map representing attention of all users, this design anticipates per-user attention maps to encode people’ attention patterns. Even more, the design embraces a user mask (a binary vector with the size equivalent to the variety of individuals) to suggest the existence of individuals in the present sample, that makes it possible to choose a group of individuals and integrate their choices into a single heatmap.
 |
| An introduction of the user conscious saliency design structure. The example image is from OSIE image set. |
Throughout reasoning, the user mask enables making forecasts for any mix of individuals. In the following figure, the very first 2 rows are attention forecasts for 2 various groups of individuals (with 3 individuals in each group) on an image. A standard attention forecast design will forecast similar attention heatmaps. Our design can differentiate the 2 groups (e.g., the 2nd group pays less attention to the face and more attention to the food than the very first). Likewise, the last 2 rows are forecasts on a website for 2 distinct individuals, with our design revealing various choices (e.g., the 2nd individual pays more attention to the left area than the very first).
 |
| Anticipated attention vs. ground fact (GT). EML-Net: forecasts from a cutting edge design, which will have the exact same forecasts for the 2 participants/groups. Ours: forecasts from our proposed user conscious saliency design, which can forecast the special choice of each participant/group properly. The very first image is from OSIE image set, and the 2nd is from FiWI |
Progressive image translating fixated prominent functions
Besides image modifying, human attention designs can likewise enhance users’ searching experience. Among the most discouraging and frustrating user experiences while searching is waiting on websites with images to load, specifically in conditions with low network connection. One method to enhance the user experience in such cases is with progressive decoding of images, which deciphers and shows significantly higher-resolution image areas as information are downloaded, till the full-resolution image is prepared. Progressive decoding generally continues in a consecutive order (e.g., delegated right, leading to bottom). With a predictive attention design ( 1, 2), we can rather decipher images based upon saliency, making it possible to send out the information needed to show information of the most prominent areas initially. For instance, in a picture, bytes for the face can be focused on over those for the out-of-focus background. As a result, users view much better image quality earlier and experience considerably lowered wait times. More information can be discovered in our open source post ( post 1, post 2). Therefore, predictive attention designs can assist with image compression and faster loading of websites with images, enhance rendering for big images and streaming/VR applications.
Conclusion
We have actually demonstrated how predictive designs of human attention can make it possible for wonderful user experiences by means of applications such as image modifying that can lower mess, interruptions or artifacts in images or images for users, and progressive image decoding that can significantly lower the viewed waiting time for users while images are completely rendered. Our user-aware saliency design can even more individualize the above applications for private users or groups, making it possible for richer and more special experiences.
Another intriguing instructions for predictive attention designs is whether they can assist enhance effectiveness of computer system vision designs in jobs such as things category or detection. For instance, in “ Teacher-generated spatial-attention labels enhance effectiveness and precision of contrastive designs“, we reveal that a predictive human attention design can assist contrastive knowing designs to accomplish much better representation and enhance the accuracy/robustness of category jobs (on the ImageNet and ImageNet-C datasets). Additional research study in this instructions might make it possible for applications such as utilizing radiologist’s attention on medical images to enhance health screening or medical diagnosis, or utilizing human attention in complicated driving situations to assist self-governing driving systems.
Recognitions
This work included collective efforts from a multidisciplinary group of software application engineers, scientists, and cross-functional factors. We want to thank all the co-authors of the papers/research, consisting of Kfir Aberman, Gamaleldin F. Elsayed, Moritz Firsching, Shi Chen, Nachiappan Valliappan, Yushi Yao, Chang Ye, Yossi Gandelsman, Inbar Mosseri, David E. Jacobes, Yael Pritch, Shaolei Shen, and Xinyu Ye. We likewise wish to thank staff member Oscar Ramirez, Venky Ramachandran and Tim Fujita for their aid. Lastly, we thank Vidhya Navalpakkam for her technical management in starting and supervising this body of work.