Picture riding to operate in your self-driving vehicle. As you approach a stop indication, rather of stopping, the vehicle accelerate and goes through the stop indication since it analyzes the stop indication as a speed limitation indication. How did this take place? Despite the fact that the vehicle’s artificial intelligence (ML) system was trained to acknowledge stop indications, somebody included sticker labels to the stop indication, which tricked the vehicle into believing it was a 45-mph speed limitation indication. This easy act of putting sticker labels on a stop indication is one example of an adversarial attack on ML systems.
In this SEI Post, I analyze how ML systems can be overturned and, in this context, describe the idea of adversarial artificial intelligence. I likewise analyze the inspirations of enemies and what scientists are doing to alleviate their attacks. Lastly, I present a fundamental taxonomy marking the methods which an ML design can be affected and demonstrate how this taxonomy can be utilized to notify designs that are robust versus adversarial actions.
What is Adversarial Artificial Intelligence?
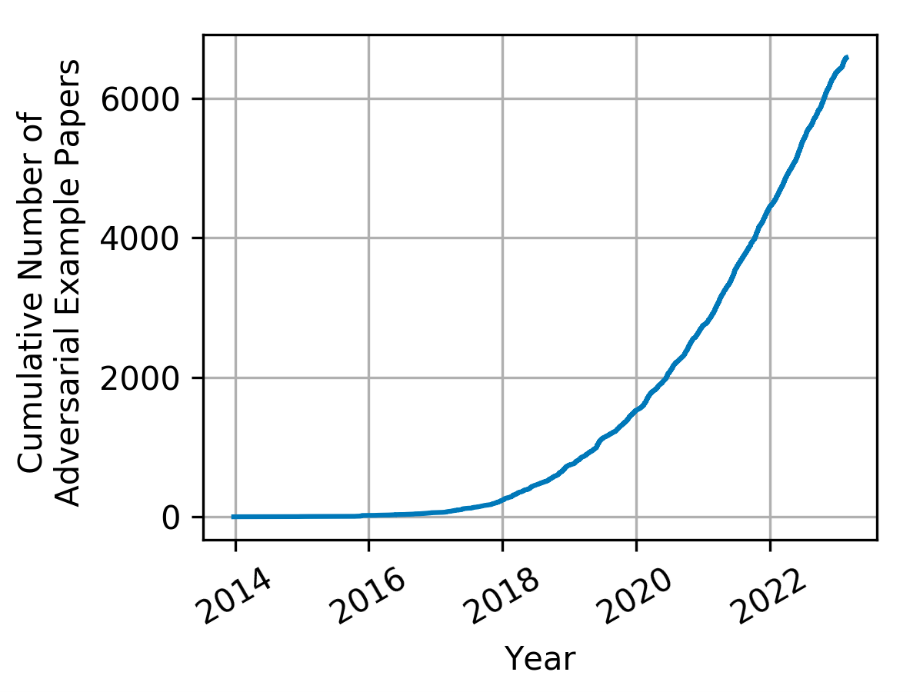
The idea of adversarial artificial intelligence has actually been around for a very long time, however the term has actually just just recently entered into usage. With the explosive development of ML and expert system (AI), adversarial strategies, methods, and treatments have actually created a great deal of interest and have actually grown substantially.
{kind=link}
When ML algorithms are utilized to develop a forecast design and after that incorporated into AI systems, the focus is usually on optimizing efficiency and guaranteeing the design’s capability to make correct forecasts (that is, reasoning). This concentrate on ability typically makes security a secondary issue to other concerns, such as effectively curated datasets for training designs, using correct ML algorithms suitable to the domain, and tuning the criteria and setups to get the very best outcomes and likelihoods. However research study has actually revealed that an enemy can put in an impact on an ML system by controling the design, information, or both. By doing so, an enemy can then require an ML system to
- find out the incorrect thing
- do the incorrect thing
- expose the incorrect thing
To counter these actions, scientists classify the spheres of impact an enemy can have on a design into a easy taxonomy of what an enemy can achieve or what a protector requires to prevent.
How Foes Look For to Impact Designs
To make an ML design find out the incorrect thing, enemies take objective at the design’s training information, any fundamental designs, or both. Foes exploit this class of vulnerabilities to affect designs utilizing techniques, such as information and criterion control, which specialists term poisoning Poisoning attacks trigger a design to improperly find out something that the enemy can make use of at a future time. For instance, an opponent may utilize information poisoning methods to corrupt a supply chain for a design created to categorize traffic indications. The opponent might make use of dangers to the information by placing triggers into training information that can affect future design habits so that the design misclassifies a stop indication as a speed limitation indication when the trigger exists (Figure 2). A supply chain attack works when a fundamental design is poisoned and after that published for others to download. Designs that are poisoned from supply chain kind of attacks can still be vulnerable to the ingrained triggers arising from poisoning the information.
{kind=link}

Attackers can likewise control ML systems into doing the incorrect thing. This class of vulnerabilities triggers a design to carry out in an unanticipated way. For example, attacks can be created to trigger a category design to misclassify by utilizing an adversarial pattern that carries out an evasion attack. Ian Goodfellow, Jonathon Shlens, and Christian Szegedy produced among the critical works of research study in this location. They included an imperceptible-to-humans adversarial sound pattern to an image, which requires an ML design to misclassify the image. The scientists took a picture of a panda that the ML design categorized effectively, then created and used a particular sound pattern to the image. The resulting image seemed the exact same Panda to a human observer (Figure 3). Nevertheless, when this image was categorized by the ML design, it produced a forecast outcome of gibbon, therefore triggering the design to do the incorrect thing.
{kind=link}

Lastly, enemies can trigger ML to expose the incorrect thing. In this class of vulnerabilities, an enemy utilizes an ML design to expose some element of the design, or the training dataset, that the design’s developer did not mean to expose. Foes can perform these attacks in numerous methods. In a design extraction attack, an enemy can produce a replicate of a design that the developer wishes to keep personal. To perform this attack, the enemy just requires to query a design and observe the outputs. This class of attack is worrying to ML-enabled application shows user interface (API) suppliers given that it can allow a consumer to take the design that allows the API.
Foes utilize design inversion attacks to expose details about the dataset that was utilized to train a design. If the enemies can acquire a much better understanding of the classes and the personal dataset utilized, they can utilize this details to open a door for a follow-on attack or to jeopardize the personal privacy of training information. The idea of design inversion was shown by Matt Fredrikson et al. in their paper Design Inversion Attacks that Make Use Of Self-confidence Details and Fundamental Countermeasures, which analyzed a design trained with a dataset of faces.
In this paper the authors showed how an enemy utilizes a design inversion attack to turn a preliminary random sound pattern into a face from the ML system. The enemy does so by utilizing a created sound pattern as an input to a qualified design and after that utilizing conventional ML systems to over and over again assist the improvement of the pattern up until the self-confidence level boosts. Utilizing the outcomes of the design as a guide, the sound pattern ultimately begins appearing like a face. When this face existed to human observers, they had the ability to connect it back to the initial individual with higher than 80 percent precision (Figure 4).
{kind=link}

Preventing Adversarial AI
Safeguarding an artificial intelligence system versus an enemy is a tough issue and a location of active research study with couple of tested generalizable services. While generalized and shown defenses are uncommon, the adversarial ML research study neighborhood is hard at work producing particular defenses that can be used to secure versus particular attacks. Establishing test and assessment standards will assist specialists determine defects in systems and assess potential defenses. This location of research study has actually become a race in the adversarial ML research study neighborhood in which defenses are proposed by one group and after that negated by others utilizing existing or recently established techniques. Nevertheless, the wide variety of elements affecting the efficiency of any protective technique prevent articulating a basic menu of protective methods tailored to the different techniques of attack. Rather, we have actually concentrated on toughness screening
ML designs that effectively prevent attacks are typically presumed to be robust, however the toughness of ML designs need to be shown through test and assessment. The ML neighborhood has actually begun to lay out the conditions and techniques for carrying out toughness examinations on ML designs. The very first factor to consider is to specify the conditions under which the defense or adversarial assessment will run. These conditions need to have a specified objective, a reasonable set of abilities your enemy has at its disposal, and an overview of just how much understanding the enemy has of the system.
Next, you need to guarantee your examinations are adaptive. In specific, every assessment needs to build on previous examinations however likewise be independent and represent a determined enemy. This method enables a holistic assessment that takes all details into account and is not excessively concentrated on one mistake circumstances or set of assessment conditions.
Lastly, clinical requirements of reproducibility need to use to your assessment. For instance, you need to be doubtful of any outcomes gotten and alert in showing the outcomes are proper and real. The outcomes gotten need to be repeatable, reproducible, and not depending on any particular conditions or ecological variables that forbid independent recreation.
The Adversarial Artificial Intelligence Laboratory at the SEI’s AI Department is investigating the advancement of defenses versus adversarial attacks. We utilize our know-how with adversarial maker discovering to enhance design toughness and the screening, measurement, and toughness of ML designs. We motivate anybody thinking about discovering more about how we can support your maker discovering efforts to connect to us at [email protected].