Clustering text files is a common concern in natural language processing (NLP). Based upon their material, associated files are to be organized. The k-means clustering method is a favored option to this concern. In this short article, we’ll show how to cluster text files utilizing k-means utilizing Scikit Learn.
K-means clustering algorithm
The k-means algorithm is a favored not being watched knowing algorithm that arranges information points into groups based upon resemblances. The algorithm runs by iteratively appointing each information indicate its closest cluster centroid and after that recalculating the centroids based upon the freshly formed clusters.
Preprocessing
Preprocessing explains the treatments utilized to get information prepared for artificial intelligence or analysis. It often includes changing, reformatting, and cleansing raw information and vectorization into a format proper for extra analysis or modeling.
Actions
- Packing or preparing the dataset [dataset link: https://github.com/PawanKrGunjan/Natural-Language-Processing/blob/main/Sarcasm%20Detection/sarcasm.json]
- Preprocessing of text in case the text is filled rather of by hand including it to the code
- Vectorizing the text utilizing TfidfVectorizer
- Minimize the measurement utilizing PCA
- Clustering the files
- Plot the cluster utilizing matplotlib
Python3
|
|
Output:
file cluster . 16263 research study discovers bulk of u.s. currency has touc ... 0 . 5318 an open and individual e-mail to hillary clinton ... 0 . 12994 it's not simply a muslim restriction, it's much even worse 0 . 5395 princeton trainees challenge university preside ... 0 . 24591 why getting wed might assist individuals consume less 0
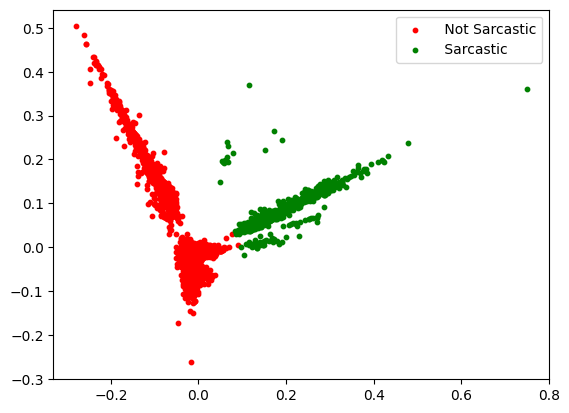
Text clustering utilizing KMeans