Among Lakehouse’s exceptional accomplishments is the capability to integrate work for contemporary usage cases, such as standard BI, artificial intelligence & & AI on one platform. This article explains an architectural pattern that alleviates the threat of “2 silos on one platform”. Following the method detailed in this blog site, information researchers utilizing Artificial intelligence and AI will have simple access to trusted information stemmed from the company’s service details design. At the exact same time, service experts can take advantage of the abilities of the lakehouse to speed up the shipment of information storage facility (DWH) tasks while keeping the core business information storage facility (EDW) steady and adhering.
We will present the idea of semantic consistency, which assists to bridge the 2 worlds of the information lake and the DWH:
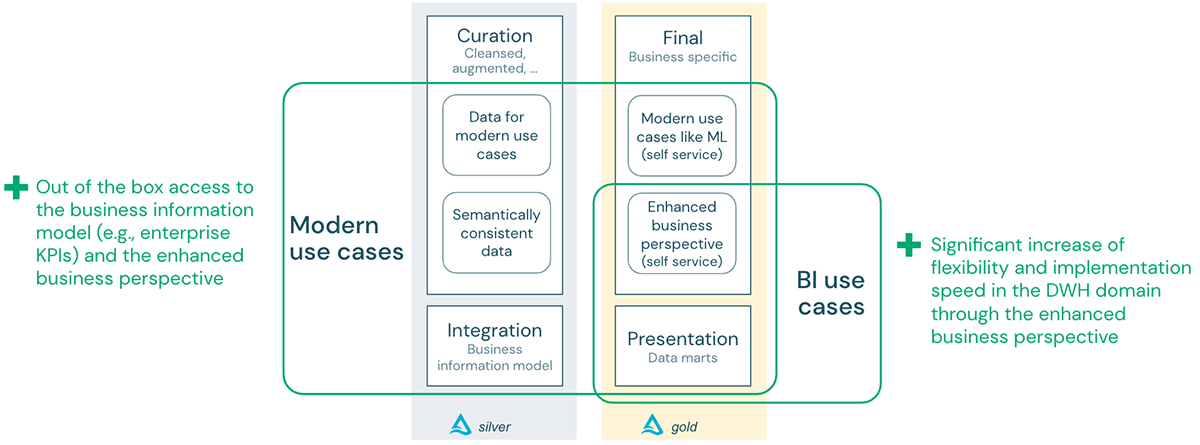
The background
In this article, we will compare contemporary usage cases on an information lake and standard BI usage cases on information storage facilities:
Information lake for contemporary usage cases: Modern usage cases generally include artificial intelligence and AI on information saved in an information lake. Both techniques intend to produce designs that forecast habits or possible results so that service users can take suitable action ahead of time.
Artificial intelligence designs are trained (monitored or not being watched) on information sets and enhanced to discover patterns or make forecasts from formerly hidden information sets. Deep knowing is a subset of artificial intelligence that utilizes algorithms motivated by the structure and function of the human brain. It becomes part of a more comprehensive household of artificial intelligence approaches based upon finding out information representations rather of standard task-specific algorithms. Artificial intelligence typically utilizes big information sets that are clearly consumed for the usage case into the information lake.
Information storage facilities are information management systems that save present and historic information from several core service options. They are imitated how a company carries out service, enabling simple insight and reporting. They draw out and aggregate information from functional databases for BI, reporting, and information analysis. The advantages of information storage facilities consist of combining information from numerous sources, offering historic details, and separating analytical processing from transactional databases. They make sure information quality and precision and standardize information by offering consistency, e.g., through calling conventions and codes for various item types, languages and currencies.
Structure an information storage facility follows a strenuous and governed procedure: Organization stars and procedures are designed in an organization details design. The information streaming through this design is shown as a rational information design (innovation agnostic) and after that executed as a physical information design depending upon the database innovation of the information storage facility. This procedure is reasonably sluggish, however it changes raw information (without service worth) into information certified with the total service context and produces actionable and reliable service details.
Typically, information warehousing was a self-questioning of a business’s service procedures. Incorporating information from those procedures generally consists of master information special to the business such as consumer stock, agreements and so forth. As increasingly more information offered to us is external information, the requirement to design this information is much less for numerous factors:
1) it is not our information and does not explain our procedures,
2) we might not completely comprehend how it connects to our “core information”, and
3) it explains something external to the business that we might wish to respond to (information signal) however need to not rise to the exact same level as “relied on details from service procedures that we run”.
Nevertheless, we still wish to have the ability to enhance our “business view” with this information to acquire brand-new insights.
And … what is the issue?
Both platforms can supply significant worth to the companies that utilize them. Nevertheless, numerous companies deal with information storage facility and information lake combination:
- The information storage facility and information lake are generally 2 silos with little or no interaction. Often information is replicated from the information lake to the information storage facility (or vice versa), producing information silos that produce brand-new issues.
- Accessing an information storage facility for contemporary usage cases can be difficult and often comes at a high expense (there might be charges for both the ML&AI platform and the information storage facility).
- Information storage facilities typically do not have assistance for integrated artificial intelligence and AI abilities. They are SQL-only and minimal in their capability to save disorganized information, such as images, or semi-structured information, such as JSON.
- Information is typically copied to the information lake without regard to total consistency. This indicates that information in the information storage facility and information in the information lake can not be combined quickly.
- The strenuous style procedure makes modifications and improvements to the DWH sluggish and costly.
Bringing both worlds together in the lakehouse
As discussed above, among Lakehouse’s exceptional accomplishments is the capability to integrate work for contemporary usage cases and standard BI on one platform. This causes numerous benefits.
So, let’s take a look at an example.
A big business runs with Salesforce (CRM) throughout its Sales cycle. When an offer is closed, an order is produced in Salesforce and forwarded to SAP through a procedure combination stage. The reasoning throughout procedure combination changes the information for ‘order’ and ‘consumer’ into the SAP information design context.
For reporting functions, the information of both systems get consumed into the Lakehouse:
- SAP information, appropriate for monetary reporting, is incorporated into the DHW part of the Lakehouse.
- Salesforce pipeline information is incorporated into the information lake part for innovative analytics, and AI utilize cases in the Lakehouse.
The information sets are predicted onto business-specific tables or BI information marts in the gold layer.
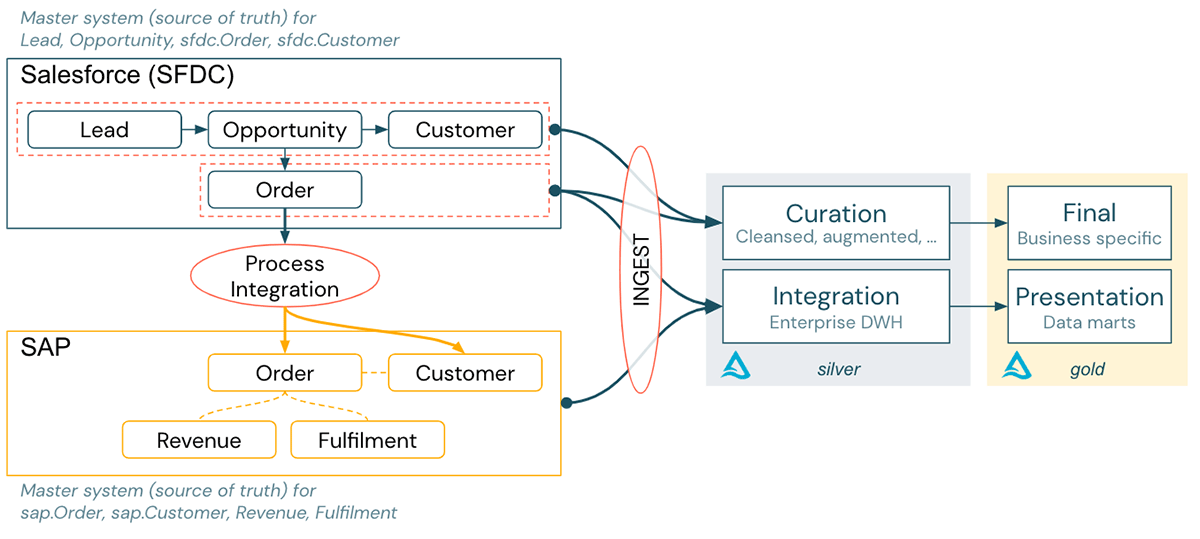
Offered this setup, we will have the ability to produce the following:
- A sales projection report from the gold layer’s business-specific information.
- A profits acknowledgment report from an information mart in the context of the total monetary reporting.
Both reports are independent, so integrating information consumed from Salesforce and SAP is not required.
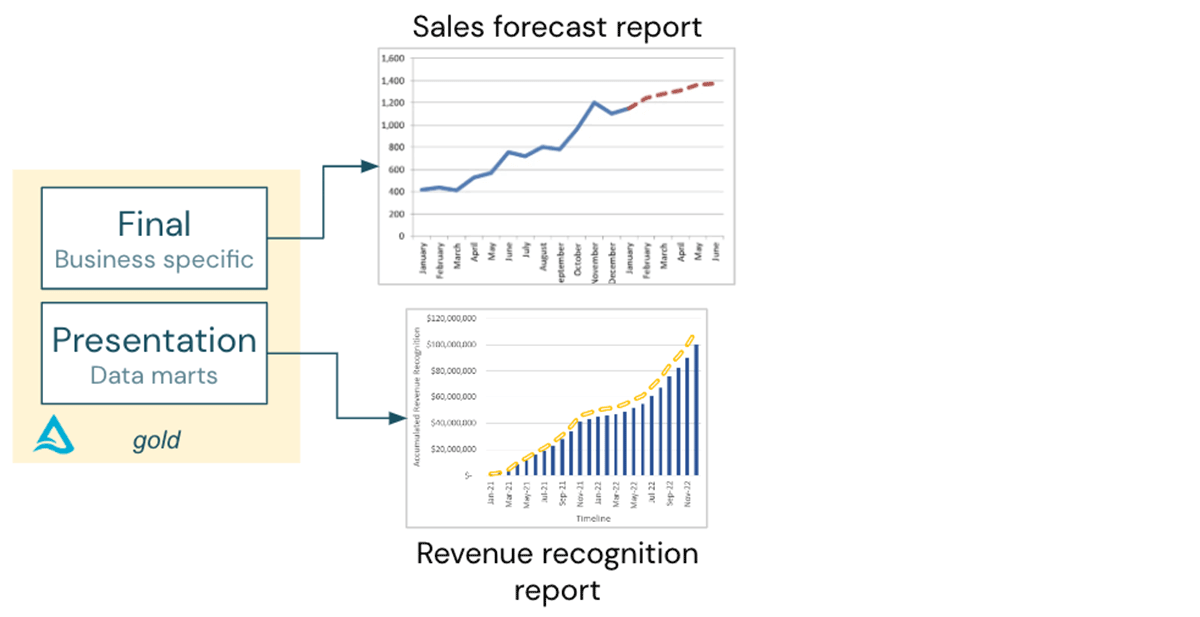
Now the CFO requests for a “earnings acknowledgment projection report”!
From an organization viewpoint, the brand-new demand from the CFO needs modeling a canonical earnings acknowledgment pattern for the business (generally, earnings gets acknowledged when a services or product has actually been provided to a client. Some services are supplied over a prolonged duration, so a design for acknowledged earnings with time is needed). This design can be streamlined however should follow the executed SAP earnings acknowledgment reasoning.
From an information viewpoint, the earnings acknowledgment projection needs integrating the sales pipeline information from Salesforce and the earnings information from SAP.
The “procedure combination” action discussed prior to uses change and service reasoning to the Salesforce entities to adhere to the requirements of the SAP information design. For this reason, one can not merely integrate information from 2 systems in the Lakehouse considering that vocabulary and granularity will most likely vary.
There are 2 choices
- Include the Salesforce items into the Combination layer (i.e., boost business details and the information designs). This method is generally sluggish and can quickly take months. In addition, these items need to just be contributed to business details design once it is shown that this report is an essential service possession.
- Combine information from the Combination layer (e.g., sap.order, earnings) with information from the curation layer (lead, chance, sfdc.order). Nevertheless, this method is just possible if the Salesforce tables in the Curation layer are semantically constant with the information in the Combination layer.
Choice 1 isn’t the simplest and fastest method, so let’s comprehend choice 2.
Semantic Consistency
What does semantically constant mean?
As typical, information consumed into the information lake is cleaned as it moves from the consumption layer to the curation layer. To make the information semantically constant, it needs to likewise be lined up in regards to service context. For instance, consumer or earnings information from various systems should have the exact same significance in both layers. And, on a proper level, the information should be de-duplicated.
This extra action makes sure that semantically constant information in the Curation layer can be safely combined with information from the Combination layer to supply business-ready tables in the gold layer: The earnings acknowledgment projection report can be effectively produced, as displayed in the following diagram.
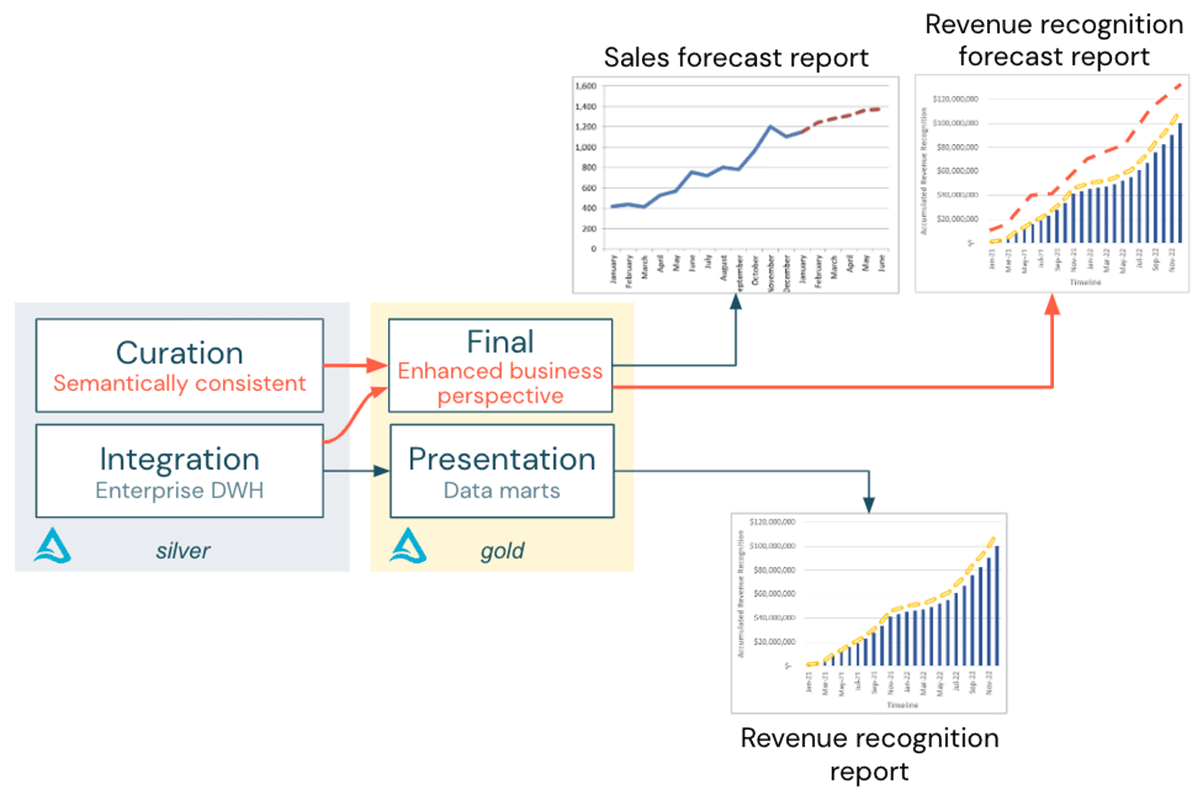
How to accomplish semantic consistency?
Let’s look once again at the SAP and Salesforce example above. The primary step we require to take is lining up terms and granularity of the tables that require signing up with:
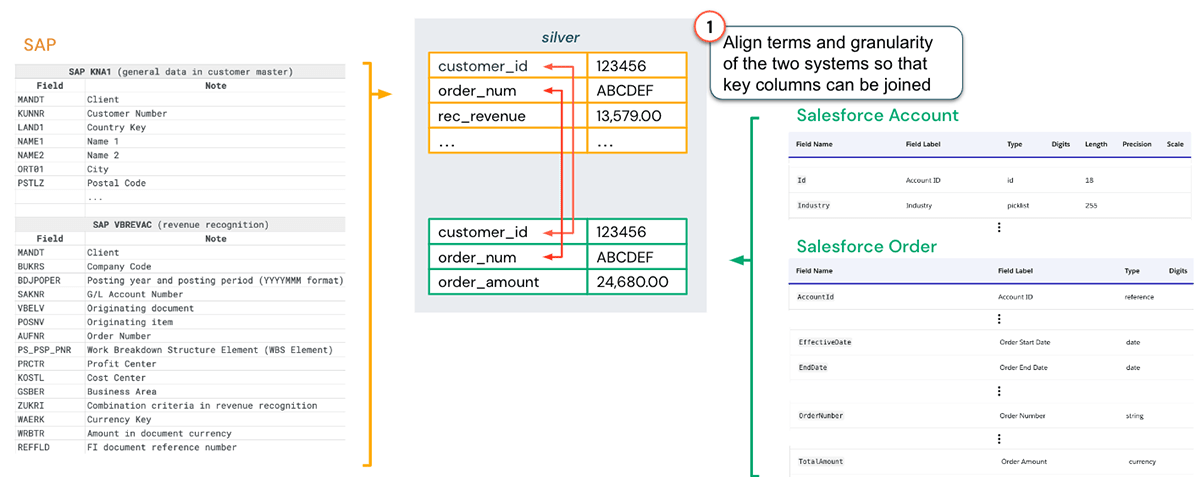
The next action is to develop earnings acknowledgment designs. An essential advantage of the Lakehouse is that information researchers can quickly access the earnings acknowledgment information from SAP saved in the information marts considering that the information is offered in the exact same system (presuming the suitable gain access to rights are approved). Offered this information, some basic earnings acknowledgment profiles can be produced, as displayed in the figure listed below.

Now that terms, granularity and the earnings acknowledgment profiles are lined up with information and reasoning in SAP, the information required for the earnings acknowledgment projection report is semantically constant and can be integrated:
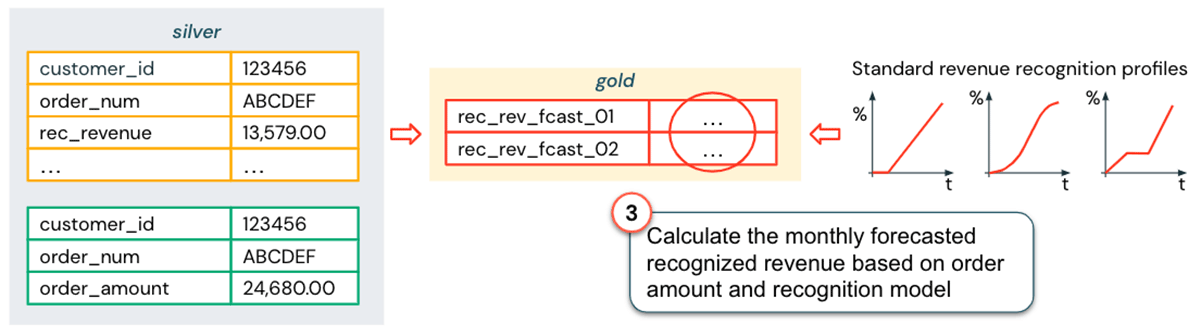
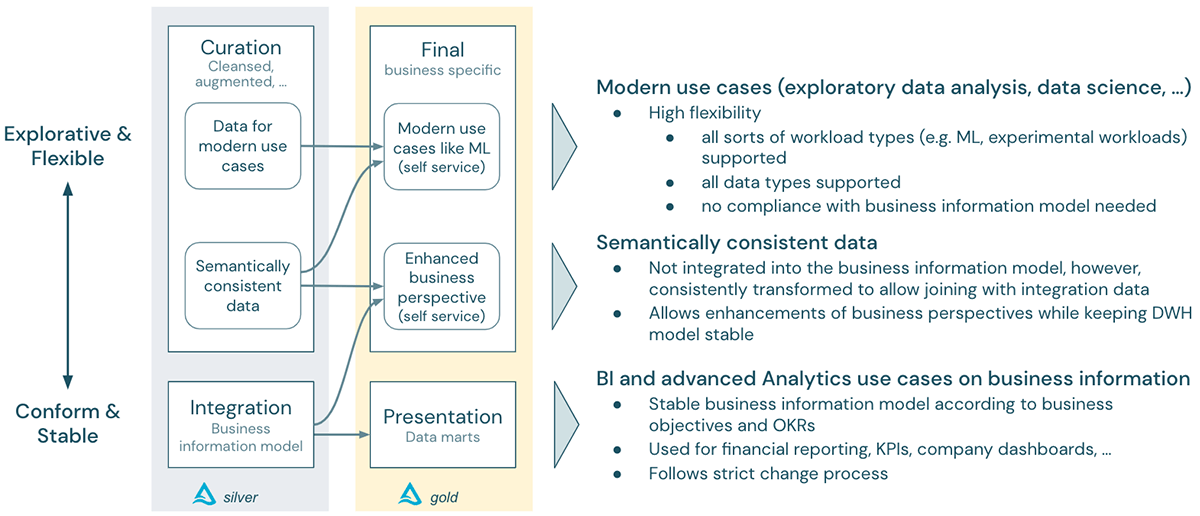
The procedure explained above is streamlined, however the basic concept ought to be clear: rather of incorporating Salesforce information holistically into business Details Design and the EDW, the Lakehouse enables us to carry out analytics utilize cases in a quicker and more versatile method: Up until we are positive that this report is a basic part of monetary reporting, we can utilize the semantic consistency method (a much smaller sized effort than a complete DWH combination) and develop an “Improved Organization Point of view” to match the views within your basic information marts.
In this method, Lakehouse assists to bridge the exploratory and versatile world of the contemporary innovative analytics utilize case paradigm with the steady and adhering paradigm of the DWH world – with both worlds gaining from running under the exact same Lakehouse platform:
Summary
Numerous companies deal with the difficulty of “2 silos” when it pertains to information storage facility and information lake combination. The lakehouse integrates work for contemporary usage cases, such as artificial intelligence and AI, and standard BI on a single platform. In this article, we presented the idea of semantic consistency, which assists bridge the 2 worlds of the information lake and the DWH, preventing the development of “2 silos in one platform”.
Using semantic consistency to information sets beyond the DWH layers that are to be integrated with information in the DWH layers has numerous advantages:
- Accomplishing semantic consistency for information outside the DWH layers is a lot easier than incorporating that information into the DWH.
- As an outcome, DWH advancement can be much faster and more exploratory while the core DWH stays steady. And if an outcome has actually shown to be of long lasting worth, the information sets can be incorporated into the DWH at a later time.
- Information researchers can quickly access information stemmed from the company’s service details design, such as service KPIs, and integrate it with semantically constant information.
- Lastly, not all information requires to be semantically constant, so the quick and exploratory nature of the information lake method is still offered for contemporary usage cases.
In time our company believe that the strictly designed part of business will be considerably grown out of by the sources beyond the core service options. However the strictly designed part of business still brings great deals of worth to the company and is important as the anchor point for getting relied on details from a contemporary information lakehouse.